Advanced searching via Z-Algorithm
I’m actually learning some stuff related to algorithms on sequences. The naive search for a pattern in a long string is of course very slow and comes with a lot of unintelligent compares. The Z-Algorithm improves the searching by preprocessing the pattern.
Naive searching
A simple search algorithm written in java may look like
public void search (String needle, String haystack)
{
for (int off = 0; off < haystack.length () - needle.length () + 1; off++)
{
boolean found = true;
for (int p = 0; p < needle.length (); p++)
if (needle.charAt (p) != haystack.charAt (off + p))
{
found = false;
break;
}
if (found) System.out.println ("Fount pattern at position " + off);
}
}This code reliably finds any existence of needle in haystack in \(O(m \cdot n)\), with \(m=\) length of needle and \(n=\) length of haystack. That screams for improvements ;)
Definitions
The first algorithm that I want to present in this series is called Z-Algorithm. First of all we need some definitions.
Definition 1: In the following we denote \(S[i\dots j]\) as the substring of \(S\) beginning at position \(i\) and ending at position \(j\). We can also leave one of the limits clear, so that \(S[i\dots]\) is the substring \(S[i\dots |S|]\) and \(S[\dots j]\) means \(S[1\dots j]\).
Definition 2: \(Z_i(S) := \max \{p | S[i \dots i+p-1] = S[1 \dots p]\}\) So \(Z_i(S)\) is the length of the longest prefix of the suffix \(S[i\dots]\) that is also prefix of \(S\) itself. To abbreviate \(Z_i(S)\) is further on mentioned as \(Z_i\).
Definition 3: The set \([i,i+Z_i-1]\) for a \(Z_i > 0\) is called Z-Box at position \(i\).
Definition 4: \(V_i := \{[a_j, b_j] | [a_j, b_j] \text{ is Z-Box at } a_j \wedge a_j < i\}\) \(V_i\) is the set of limits of all Z-Box’es that start at the left-handed side of \(i\). Consider \(i<j \Rightarrow V_i \subseteq V_j\).
Definition 5: \([l_i,r_i] := \begin{cases} \underset{b_j}{\arg\max} \ [a_j,b_j] \in V_i, & \text{if } V_i \ne \varnothing\\ [0,0] & \text{else}\end{cases}\) If \(l_i>0\) and \(r_i>0\), \([l_i,r_i]\) defines the rightest Z-Box that starts before respectively at position \(i\). Consider \(i<j \Rightarrow r_i\le r_j\).
Algorithm
In the following \(i\) will denote the actual position we are looking for, \(l\) and \(r\) describe the current respectively last found of a Z-Box. First of all we set the values \(l\) and \(r\) to zero because we haven’t found any Z-Box yet. \(Z_2\) of our text \(S\) is according to Definition 2 the length of the longest prefix of \(S[2\dots]\) that is also prefix of \(S\) itself. If \(Z_2>0\) we found a first Z-Box and update the limits to \(l=2\) and \(r=2+Z_2-1\).
Now we have to run through the word \(S\), so \(i=3\dots \|S\|\) with \(\|S\|\) defines the length of \(S\).
Case 1: Let’s assume position \(i\) is outside of the last found Z-Box or we didn’t find any Z-Box yet (\(i>r\)). We find \(Z_i\) by comparing the prefixes of \(S\) and \(S[i\dots]\). If \(Z_i>0\) we’ve found a new Z-Box and need to update the limits to \(l=i\) and \(r=i+Z_i-1\).
Case 2: If the current position \(i\) is inside of a current Z-Box (\(i\le r\)) we try to find the equivalent position at the beginning of \(S\). The position we are searching for is \(k=i-l+1\) steps off the beginning of \(S\) (we are \(i-l+1\) steps behind \(l\) and \(S[l\dots]\) has the same prefix as \(S\)). Case 2a: If we don’t break out of the current Z-Box by creating another Z-Box with the length of the box at position \(k\) (\(Z_k<r-i+1\), so position \(i+Z_k\) is not behind position \(r\)), we can simply apply this Z-Box to the current position and \(Z_i=Z_k\). Case 2b: Otherwise, if we would leave the actual Z-Box (\(i + Z_k>r\)) we have to recheck the prefix conditions of \(S[i\dots]\) and \(S\). We know that \(S[i\dots r]\) equals \(S[1\dots r-i+1]\), so we only have to find the length of the longest prefix \(p\) of \(S[r-i+2\dots]\) that equals the prefix of \(S[r+1\dots]\). Now we can apply the new Z-Box such that \(Z_i=r-i+1+p\) and of course we update the Z-Box limits to \(l=i\) and \(r=i+Z_i-1\).
If we reached the end of \(S\) all Z-Boxes are found in \(\Theta(\|S\|)\).
Pseudo code
l = r = 0
Z[2] = prefix (S, S[2 ..]).length
if Z[2] > 0 then
l = 2
r = 2 + Z[2] - 1
for i = 3..|S| do
if i > r then '(case 1)'
Z[i] = prefix (S, S[i ..]).length
if Z[i] > 0 then
l = i
r = i + Z[i] - 1
else '(case 2)'
k = i - l + 1
if Z[k] < r - i + 1 then '(case 2a)'
Z[i] = Z[k]
else '(case 2b)'
p = prefix (S[r - i + 2 ..], S[r + 1 ..]).length
Z[i] = r - i + 1 + p
l = i
r = i + Z[i] - 1Example
Let me demonstrate the algorithm with a small example. Let’s take the word \(S=aabaaab\). First we start with \(l=0\) and \(r=0\) at position 2. \(Z_2\) is the length of the shared prefix of \(S\) (\(aabaaab\)) and \(S[2\dots]\) (\(abaaab\)). Easy to see the prefix is \(a\) with a length of 1. So \(Z_2=1\), \(l=2\) and \(r=2\). At the beginning of our for-loop the program’s status is:
| $$T$$ | a | a | b | a | a | a | b |
|---|---|---|---|---|---|---|---|
| $$i$$ | 1 | 2 | |||||
| $$Z_i$$ | 1 | ||||||
| $$l$$ | 2 | ||||||
| $$r$$ | 2 |
At the first round in the loop \(i=3\), so \(i>r\) because \(r=2\). So we meet case 1 and have to find the length of the prefix of \(S\) (\(aabaaab\)) and \(S[3\dots]\) (\(baaab\)). Of course it’s zero, nothing to do.
| $$T$$ | a | a | b | a | a | a | b |
|---|---|---|---|---|---|---|---|
| $$i$$ | 1 | 2 | 3 | ||||
| $$Z_i$$ | 1 | 0 | |||||
| $$l$$ | 2 | 2 | |||||
| $$r$$ | 2 | 2 |
Next round, we’re at position 4 and again \(i>r\) (case 1). So we have to compare \(aabaaab\) and \(aaab\). The longest prefix of both words is \(aa\) with a length of 2. So we start a new Z-Box at 4 with a size of 2, so \(l=4\) and \(r=5\).
| $$T$$ | a | a | b | a | a | a | b |
|---|---|---|---|---|---|---|---|
| $$i$$ | 1 | 2 | 3 | 4 | |||
| $$Z_i$$ | 1 | 0 | 2 | ||||
| $$l$$ | 2 | 2 | 4 | ||||
| $$r$$ | 2 | 2 | 5 |
With \(i=5\) and \(r=5\) we reach case 2 for the first time. \(k=i-l+1=2\) so our similar position at the beginning of \(S\) is position 2. \(Z_2=1\) and \(r-i+1=1\) so we are in case 2b and have to find the shared prefix of \(S[2 ..]\) (\(abaaab\)) and \(S[6 ..]\) (\(ab\)). It’s \(ab\), so \(p=2\) and \(Z_5=r-i+1+p=3\). \(l=5\) and \(r=7\).
| $$T$$ | a | a | b | a | a | a | b |
|---|---|---|---|---|---|---|---|
| $$i$$ | 1 | 2 | 3 | 4 | 5 | ||
| $$Z_i$$ | 1 | 0 | 2 | 3 | |||
| $$l$$ | 2 | 2 | 4 | 5 | |||
| $$r$$ | 2 | 2 | 5 | 7 |
Next round brings us \(i=6<r\), therefor we’re in case 2. Equivalent position is again \(k=i-l+1=2\), but now \(Z_2=1<r-i+1=2\) and we’re in case 2a and can just set \(Z_6=1\).
| $$T$$ | a | a | b | a | a | a | b |
|---|---|---|---|---|---|---|---|
| $$i$$ | 1 | 2 | 3 | 4 | 5 | 6 | |
| $$Z_i$$ | 1 | 0 | 2 | 3 | 1 | ||
| $$l$$ | 2 | 2 | 4 | 5 | 5 | ||
| $$r$$ | 2 | 2 | 5 | 7 | 7 |
The last round we have to process is \(i=7<r\), case 2. Equivalent position is \(k=i-l+1=3\) and \(Z_3=0<r-i+1=1\), so case 2a and \(Z_7 = 0\).
| $$T$$ | a | a | b | a | a | a | b |
|---|---|---|---|---|---|---|---|
| $$i$$ | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| $$Z_i$$ | 1 | 0 | 2 | 3 | 1 | 0 | |
| $$l$$ | 2 | 2 | 4 | 5 | 5 | 5 | |
| $$r$$ | 2 | 2 | 5 | 7 | 7 | 7 |
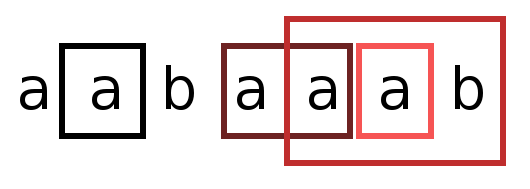
That’s it. The Z-Box’es we’ve found are visualized in the image.
Searching
To search for a pattern \(P \in A^*\) in a text \(T \in A^*\) just calculate the Z-Boxes of \(P\$T\) with \(\$\notin A\). These calculations are done in \(\Theta(|T|)\). For any \(i>|P|\): If \(Z_i=|P|\) means \(P\$T[i\dots i+|P|-1]\) is prefix of \(P\$T\), so \(P\) is found at position \(i-(|P|+1)\) in \(T\).
Code
Of course I’m providing an implementation, see attachment.
- bioinformatics (22) ,
- explained (44) ,
- java (23) ,
- pattern (3) ,
- programming (75) ,
- search (5) ,
- university (42)

Martin Scharm
Leave a comment
There are multiple options to leave a comment:
- send me an email
- submit a comment through the feedback page (anonymously via TOR)
- Fork this repo at GitHub, add your comment to the _data/comments directory and send me a pull request
- Fill the following form and Staticman will automagically create a pull request for you:
1 comment
Suffix trees…
Suffix trees are an application to particularly fast implement many important string operations like searching for a pattern or finding the longest common substring…….