web content anlayzer
Just developed a small crawler to check my online content at binfalse.de in terms of W3C validity and the availability of external links. Here is the code and some statistics…
The new year just started and I wanted to check what I produced the last year in my blog. Mainly I wanted to ensure more quality, my aim was to make sure all my blog content is W3C valid and all external resources I’m linking to are still available. First I thought about parsing the database-content, but at least I decided to check the real content as it is available to all of you. The easiest way to do something like this is doing it with Perl, at least for me. The following task were to do for each site of my blog:
- Check if W3C likes the site
- For each link to external resources: Check if they respond with
200 OK - For each internal link: Check this site too if not already checked
While I’m checking each site I also saved the number of leaving links to a file to get an overview. Here is the code:
You need to install LWP::UserAgent , XML::TreeBuilder and WebService::Validator::HTML::W3C . Sitting in front of a Debian based distribution just execute:
aptitude install libxml-treebuilder-perl libwww-perl libwebservice-validator-css-w3c-perl libxml-xpath-perlThe script checks all sites that it can find and that match to
m/^(http(s)?:\\/\\/)?[^\\/]*$domain/iSo adjust the $domain variable at the start of the script to fit your needs.
It writes all W3C results to /tmp/check-links.val , the following line-types may be found within that file:
# SITE is valid
ok: SITE
# SITE contains invalid FAILURE at line number LINE
error: SITE -> FAILURE (LINE)
# failed to connect to W3C because of CAUSE
failed: CAUSESo it should be easy to parse if you are searching for invalids.
Each external link that doesn’t answer with 200 OK produces an entry to /tmp/check-links.fail with the form
SITE -> EXTERNAL (RESPONSE_CODE)Additionally it writes for each website the number of internal links and the number of external links to /tmp/check-links.log .
If you want to try it on your site keep in mind to change the content of $domain and take care of the pattern in line 65:
$href =~ m/\\/$/Because I don’t want to check internal links to files like .png or .tgz the URL has to end with / . All my sites containing parseable XML end with / , if your sites doesn’t, try to find a similar expression.
As I said I’ve looked to the results a bit. Here are some statistics (as at 2011/Jan/06):
| Processed sites | 481 |
| Sites containing W3C errors | 38 |
| Number of errors | 63 |
| Mean error per site | 0.1309771 |
| Mean of internal/external links per site | 230.9833 / 15.39875 |
| Median of internal/external links per site | 216 / 15 |
| Dead external links | 82 |
| Dead external links w/o Twitter | 5 |
Most of the errors are now repaired, the other ones are in progress.
The high number of links that aren’t working anymore comes from the little twitter buttons at the end of each article. My crawler is of course not authorized to tweet, so twitter responds with 401 Unauthorized . One of the other five fails because of a cert problem, all administrators of the other dead links are informed.
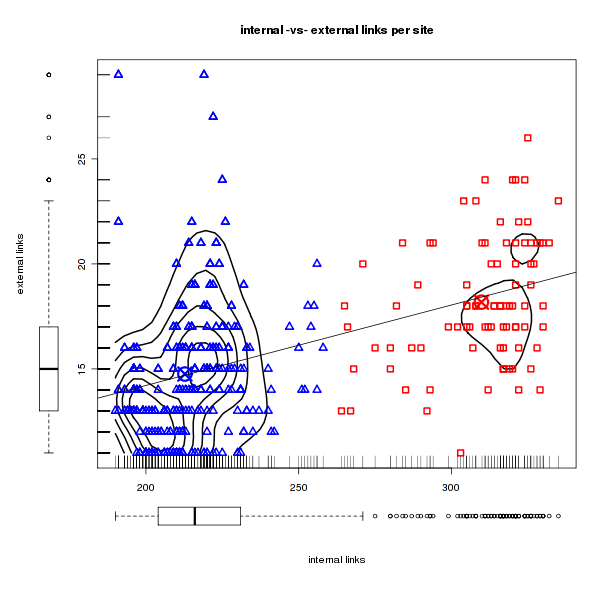
I also analyzed the outgoing links per site. I’ve clustered them with K-Means, the result can be seen in figure 1. How did I produce this graphic? Here is some R code:
library(MASS)
x=read.table("check-links.log")
intern=x[,1]
extern=x[,2]
z <- kde2d(intern,extern, n=50)
# cluster
colnames(x) <- c("internal", "external")
(cl <- kmeans(x, 2))
# draw
png("check-links.png", width = 600, height = 600)
# save actual settings
op <- par()
layout( matrix( c(2,1,0,3), 2, 2, byrow=T ), c(1,6), c(4,1))
par(mar=c(1,1,5,2))
contour(z, col = "black", lwd = 2, drawlabels = FALSE)
points(x, col = 2*cl$cluster, pch = 2 * (cl$cluster - 1),lwd=2,cex=1.3)
points(cl$centers, col = c(2,4), pch = 13, cex=3,lwd=3)
rug(side=1, intern )
rug(side=2, extern )
abline(lm( external ~ internal, data = x))
title(main = "internal -vs- external links per site")
# boxplot left
par(mar=c(1,2,5,1))
boxplot(extern, axes=F)
title(ylab='external links', line=0)
# boxplot right
par(mar=c(5,1,1,2))
boxplot(intern, horizontal=T, axes=F)
title(xlab='internal links', line=1)
# restore settings
par(op)
dev.off()You’re right, there is a lot stuff in the image that is not essential, but use it as example to show R beginners what is possible. Maybe you want to produce similar graphics!?
- analyzed (15) ,
- blog (17) ,
- clustering (4) ,
- gnu (22) ,
- media (61) ,
- network (81) ,
- private (31) ,
- programming (75)

Leave a comment
There are multiple options to leave a comment: