binfalse
MFC-9120CN Setup
September 1st, 2012I just bought a new printer, the Brother MFC-9120CN. It’s also able to scan and to copy documents and to send them by fax. Since the installation instructions are win/mac-only I’ll shortly explain how to setup the device in a Linux environment.

Decision for this printer
First of all I was searching for a printer that is in any case compatible to Linux systems. You might also have experiences with this driver f$ckup, or at least have heard about it. The manufactures often only provide drivers for Win or Mac, so you generally get bugged if you want to integrate those peripherals in your environment. The MFC-9120CN scores at this point. It is able to print and scan via network. Drivers for the printer are available and the the scanned documents can be sent at any FTP server. So you don’t need to have special drivers for scanning, just setup a small FTP server. This model is also a very cheap one compared to other color-laser MFP’s, and with the ADF it completely matches my criteria.
Disadvantages
I already noticed some disadvantages. One is the speed, the printer is somewhat slow. Since I’m not printing thousands of pages it’s more or less minor to me, but you should be aware of that. Another issue is the fact, that the device always forgets the date if it is turned of for a time.. And the printer is a bit too noisy.
Setup
The printer comes with a large user manual (>200 pages). It well explains setup the fax functionality, but the installation of the network printer and scanner is only described for win/mac, so I’ll give you a small how-to for your Linux systems.
Network Setup
To use this device via network you have to connect it to a router. It should be able to request an IP via DHCP, but if you don’t provide a DHCP server you need to configure the network manually (my values are in parenthesis):
- IP:
menu->5->1->2(192.168.9.9) - Netmask:
menu->5->1->3(255.255.255.0) - Gateway:
menu->5->1->4(192.168.9.1)
If this is done you should be able to ping the printer:
usr@srv % ping 192.168.9.9
PING 192.168.9.9 (192.168.9.9) 56(84) bytes of data.
64 bytes from 192.168.9.9: icmp_req=1 ttl=255 time=0.306 ms
[...]If you browse to this IP using your web browser you’ll find a web interface for the printer. We’ll need this website later on.
Printer Setup
Big thanks to the CUPS project, it’s very easy to setup the network-printer! If you haven’t installed cups yet, do it now:
aptitude install cups foomatic-dbJust browse to your CUPS server (e.g. http://localhost:631 if it is installed on your current machine) and install a new printer via Administration->add Printer (you need to be root). Recent CUPS versions will detect the new printer automatically and you’ll find it in the list of Discovered Network Printers. Just give it a name and some description, select a driver (I’m using Brother MFC-9120CN BR-Script3 (color, 2-sided printing)) and you’re done! Easy, isn’t it!? ;-)
For those of you that have an older version of CUPS: The URI of my printer is dnssd://Brother%20MFC-9120CN._printer._tcp.local/ .
Scanner Setup
As explained above, the printer is able to send scanned documents to a FTP location. That is, there is no need for a scanner driver! Just install a small FTP server, I decided for ProFTPd:
aptitude install proftpd-basicMake sure, that the /etc/proftpd/proftpd.conf contains the following lines:
DefaultRoot ~
RequireValidShell off
AuthOrder mod_auth_file.c mod_auth_unix.c
AuthUserFile /etc/proftpd/ftpd.passwd
AuthPAM offand create a new virtual FTP user:
ftpasswd --passwd --name YourPrinter --uid 10001 --home /PATH/TO/FILES --shell /bin/falseYou will be asked for a password. The scanned documents will be stored in /PATH/TO/FILES . This command creates a file ftpd.passwd . Move this file to /etc/proftpd/ , if you didn’t execute the command in that directory.
Restart ProFTPd:
/etc/init.d/proftpd restartYou should be able to connect to your FTP server:
usr@srv % ftp localhost
Connected to localhost.
220 ProFTPD 1.3.4a Server (Debian) [::ffff:127.0.0.1]
Name (localhost:you): YourPrinter
500 AUTH not understood
500 AUTH not understood
SSL not available
331 Password required for printer
Password:
230 User printer logged in
Remote system type is UNIX.
Using binary mode to transfer files.
ftp> ls
200 PORT command successful
150 Opening ASCII mode data connection for file list
[...]
226 Transfer complete
ftp> quit
221 Goodbye.If that was successful, let’s configure the scanner to use this FTP account. Use your web browser to open the interface of the printer (e.g. http://192.168.9.9/) and go to Administrator Settings->FTP/Network Scan Profile (you have to authenticate, default login is admin and the password is access). Here you’ll find 10 different profiles that can be configured. Click for example on Profile Name 1 and modify the profile:
- Host Address: The IP of the FTP server (e.g.
192.168.9.10) - Username: The username of the virtual FTP user you’ve created (e.g.
YourPrinter) - Password and Retype Password: The password of the virtual FTP
- Store Directory:
/
If you submit these values you’ll be able to scan to your FTP server. Just give it a try! ;-)
Additional Notes
I recommend to configure your firewall to drop all packets of your printer that try to leave your own network.
Conditionally autoscroll a JScrollPane
April 10th, 2012I’m currently developing some GUI stuff and was wondering how to let a JScrollPane scroll automatically if it’s already on the bottom and the size of it’s content increases.
For example if you use a JTextArea to display some log or whatever, than it would be nice if the scroll bars move down while there are messages produced, but it shouldn’t scroll down when the user just scrolled up to read a specific line. To scroll down to the end of a JTextArea can be done with just setting the carret to the end of the text:
JTextArea log = new JTextArea (20, 20);
log.setEditable (false);
JScrollPane scroller = new JScrollPane ();
scroller.setViewportView (output);
// [...]
log.append ("your message");
log.setCaretPosition (log.getDocument ().getLength ());But we first want to check whether the scroll bar is already at the bottom, and only if that’s the case it should automatically scroll down to the new bottom if another message is inserted. To obtain the position data of the vertical scroll bar on can use the following code:
JScrollBar vbar = scroller.getVerticalScrollBar ();
// get the current position
int currentPosition = vbar.getValue ();
// getMaximum () gives maximum + extent.
int maxPosition = vbar.getMaximum () - vbar.getVisibleAmount ();
if (currentPosition == maxPosition)
{
// in this case we want to scroll after the new text is appended
}Unfortunately log.append ("some msg") won’t append the text in place, so the size of the text area will not necessarily change before we ask for the new maximum position. To avoid a wrong max value one can also schedule the scroll event:
private void logText (String text)
{
final JScrollBar vbar = scroller.getVerticalScrollBar ();
// is the scroll bar at the bottom?
boolean end = vbar.getMaximum () == vbar.getValue () + vbar.getVisibleAmount ();
// append some new text to the text area
// (or do something else that increases the contents of the JScrollPane)
log.append (text + "\\n");
// if scroll bar already was at the bottom we schedule
// a new scroll event to again scroll to the bottom
if (end)
{
EventQueue.invokeLater (new Runnable ()
{
public void run ()
{
EventQueue.invokeLater (new Runnable ()
{
public void run ()
{
vbar.setValue (vbar.getMaximum ());
}
});
}
});
}
}As you can see, here a new event is put in the EventQueue, and this event is told to put another event in the queue that will do the scroll event. Correct, that’s a bit strange, but the swing stuff is very lazy and it might take a while until the new maximum position of the scroll bar is calculated after the whole GUI stuff is re-validated. So let’s be sure that our event definitely happens when all dependent swing events are processed.
galternatives
April 5th, 2012Some days ago I discovered galternatives, a GNOME tool to manage the alternatives system of Debian/Ubuntu. It’s really smart I think.
For example to update the default editor for your system you need to update the alternatives system via:
update-alternatives --set editor /usr/bin/vim
There is also an interactive version available:
update-alternatives --config editor
To see available browsers you need to run
update-alternatives --list x-www-browser
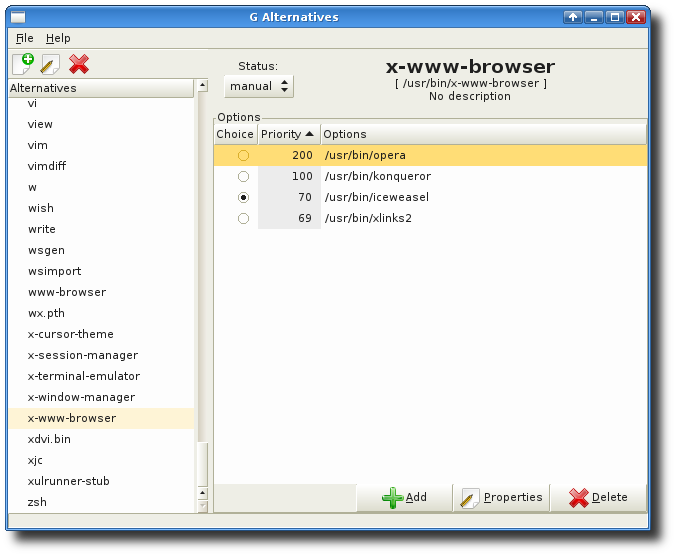
However, the alternatives system is a nice idea I think, but it’s a bit confusing sometimes. And installing a new group or adding another entry to an existing group is pretty complicated and requires information from multiple other commands beforehand.
With galternatives you’ll get a graphical interface to manage all these things. That really brings light into the dark! Just install it via
aptitude install galternatives
You’ll be astonished if you give it a try! ;-)
YOURLS Firefox Extension Version 1.4
April 2nd, 2012I submitted a new version of the YOURLS Firefox extension.
It just contains some minor changes, but I want to inform my loyal readers! The add-on is currently in the review queue, hopefully this time I’ll get a complete review by the AMO-team ;-)
If you’re crazy you can try the new version, it’s available on SourceForge and on AMO.
UPDATE: I just received a fully review, so my add-on is finally stable!!
J-vs-T goes Java
April 1st, 2012I just ported the Jabber -vs- Twitter bridge to Java.
That was a point on my todo list for a long time, because I hate the hacked stuff from the improvised Perl solution. And in the end I finally did it ;-)
You can find the new XMPP to Twitter bridge with the name XTB in my sidebar. It’s now written in nice Java code, easy to understand and much easier to work with! So feel free to give it a try!
End of announcement! :P
