Comparison of compression
I recently wrote an email with an attached LZMA archive. It was immediately answered with something like:
What are you doing? I had to boot linux to open the file!
First of all I don’t care whether user of proprietary systems are able to read open formats, but this answer made me curious to know about the differences between some compression mechanisms regarding compression ratio and time. So I had to test it!
This is nothing scientific! I just took standard parameters, you might optimize each method on its own to save more space or time. Just have a look at the parameter -1..-9 of zip. But all in all this might give you a feeling for the methods.
Candidates
I’ve chosen some usual compression methods, here is a short digest (more or less copy&paste from the man pages):
- gzip: uses Lempel-Ziv coding (LZ77), cmd:
tar czf $1.pack.tar.gz $1 - bzip2: uses the Burrows-Wheeler block sorting text compression algorithm and Huffman coding, cmd:
tar cjf $1.pack.tar.bz2 $1 - zip: analogous to a combination of the Unix commands tar(1) and compress(1) and is compatible with PKZIP (Phil Katz’s ZIP for MSDOS systems), cmd:
zip -r $1.pack.zip $1 - rar: proprietary archive file format, cmd:
rar a $1.pack.rar $1 - lha: based on Lempel-Ziv-Storer-Szymanski-Algorithm (LZSS) and Huffman coding, cmd:
lha a $1.pack.lha $1 - lzma: Lempel-Ziv-Markov chain algorithm, cmd:
tar --lzma -cf $1.pack.tar.lzma $1 - lzop: imilar to gzip but favors speed over compression ratio, cmd:
tar --lzop -cf $1.pack.tar.lzop $1
All times are user times, measured by the unix time command. To visualize the results I plotted them using R, compression efficiency at X vs. time at Y. The best results are of course located near to the origin.
Data
To test the different algorithms I collected different types of data, so one might choose a method depending on the file types.
Binaries
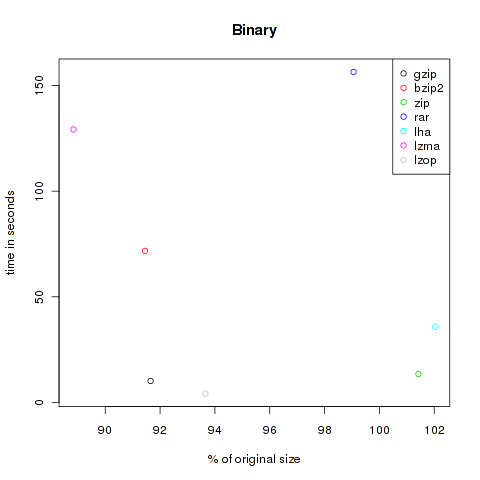
The first category is called binaries. A collection of files in human-not-readable format. I copied all files from /bin and /usr/bin , created a gpg encrypted file of a big document and added a copy of grml64-small_2010.12.iso. All in all 176.753.125 Bytes.
| Method | Compressed Size | % of original | Time in s |
|---|---|---|---|
| gzip | 161.999.804 | 91.65 | 10.18 |
| bzip2 | 161.634.685 | 91.45 | 71.76 |
| zip | 179.273.428 | 101.43 | 13.51 |
| rar | 175.085.411 | 99.06 | 156.46 |
| lha | 180.357.628 | 102.04 | 35.82 |
| lzma | 157.031.052 | 88.84 | 129.22 |
| lzop | 165.533.609 | 93.65 | 4.16 |
Media
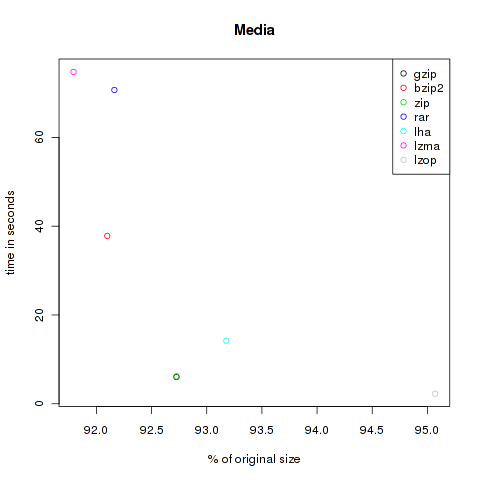
This is a bunch of media files. Some audio data like the I have a dream-speech of Martin-Luther King and some music. Also video files like the The Free Software Song and Clinton’s I did not have sexual relations with that woman are integrated. I attached importance to different formats, so here are audio files of the type ogg, mp3 mid, ram, smil and wav, and video files like avi, ogv and mp4. Altogether 95.393.277 Bytes.
| Method | Compressed Size | % of original | Time in s |
|---|---|---|---|
| gzip | 88.454.002 | 92.73 | 6.04 |
| bzip2 | 87.855.906 | 92.10 | 37.82 |
| zip | 88.453.926 | 92.73 | 6.17 |
| rar | 87.917.406 | 92.16 | 70.69 |
| lha | 88.885.325 | 93.18 | 14.22 |
| lzma | 87.564.032 | 91.79 | 74.76 |
| lzop | 90.691.764 | 95.07 | 2.28 |
Office
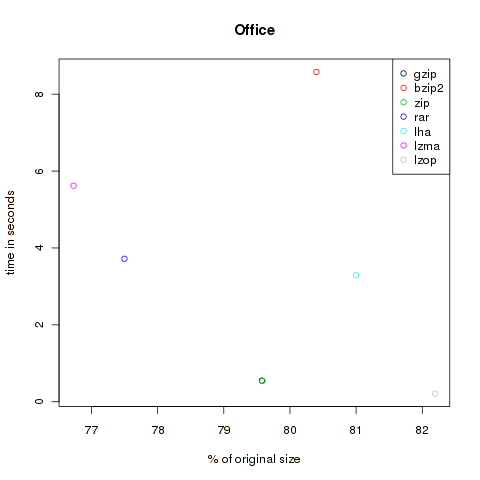
The next category is office. Here are some PDF from different journals and office files from LibreOffice and Microsoft’s Office (special thanks to @chschmelzer for providing MS files). The complete size of these files is 10.168.755 Bytes.
| Method | Compressed Size | % of original | Time in s |
|---|---|---|---|
| gzip | 8.091.876 | 79.58 | 0.55 |
| bzip2 | 8.175.629 | 80.40 | 8.58 |
| zip | 8.092.682 | 79.58 | 0.54 |
| rar | 7.880.715 | 77.50 | 3.72 |
| lha | 8.236.422 | 81.00 | 3.29 |
| lzma | 7.802.416 | 76.73 | 5.62 |
| lzop | 8.358.343 | 82.20 | 0.21 |
Pictures
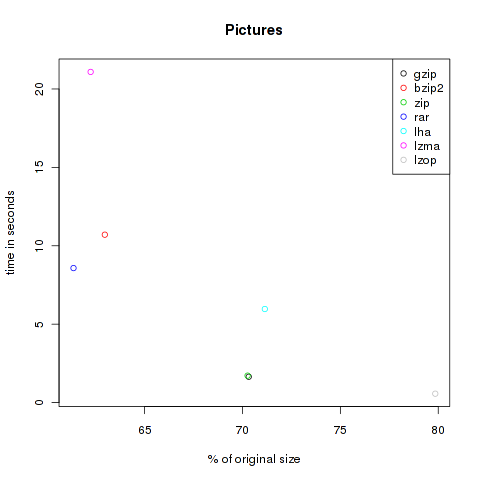
To test the compression of pictures I downloaded 10 files of each format bmp, eps, gif, jpg, png, svg and tif. That are the first ones I found with google’s image search engine. In total 29’417’414 Bytes.
| Method | Compressed Size | % of original | Time in s |
|---|---|---|---|
| gzip | 20.685.809 | 70.32 | 1.65 |
| bzip2 | 18.523.091 | 62.97 | 10.71 |
| zip | 20.668.602 | 70.26 | 1.72 |
| rar | 18.052.688 | 61.37 | 8.58 |
| lha | 20.927.949 | 71.14 | 5.97 |
| lzma | 18.310.032 | 62.24 | 21.09 |
| lzop | 23.489.611 | 79.85 | 0.57 |
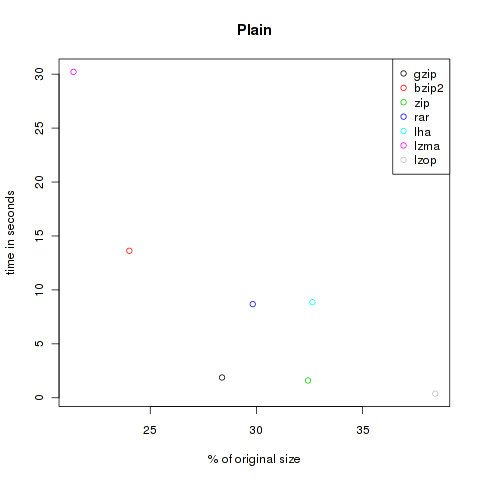
Plain
This is the main category. As you know, ASCII content is not saved really space efficient. Here the tools can riot! I downloaded some books from Project Gutenberg, for example Jules Verne’s Around the World in 80 Days and Homer’s The Odyssey, source code of moon-buggy and OpenLDAP, and copied all text files from /var/log . Altogether 40.040.854 Bytes.
| Method | Compressed Size | % of original | Time in s |
|---|---|---|---|
| gzip | 11.363.931 | 28.38 | 1.88 |
| bzip2 | 9.615.929 | 24.02 | 13.63 |
| zip | 12.986.153 | 32.43 | 1.6 |
| rar | 11.942.201 | 29.83 | 8.68 |
| lha | 13.067.746 | 32.64 | 8.86 |
| lzma | 8.562.968 | 21.39 | 30.21 |
| lzop | 15.384.624 | 38.42 | 0.38 |
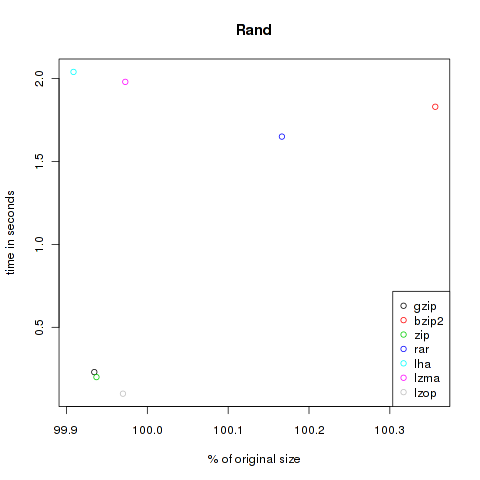
Rand
This category is just to test random generators. Compressing random content shouldn’t decrease the size of the files. Here I used two files from random.org and dumped some bytes from /dev/urandom. 4.198.400 Bytes.
| Method | Compressed Size | % of original | Time in s |
|---|---|---|---|
| gzip | 4.195.646 | 99.93 | 0.23 |
| bzip2 | 4.213.356 | 100.36 | 1.83 |
| zip | 4.195.758 | 99.94 | 0.2 |
| rar | 4.205.389 | 100.17 | 1.65 |
| lha | 4.194.566 | 99.91 | 2.04 |
| lzma | 4.197.256 | 99.97 | 1.98 |
| lzop | 4.197.134 | 99.97 | 0.1 |
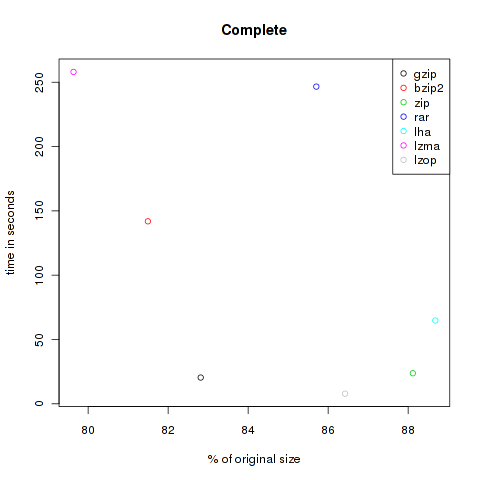
Everything
All files of the previous catergories compressed together. Since the categories aren’t of same size it is of course not really fair. Nevertheless it might be interesting. All files together require 355.971.825 Bytes.
| Method | Compressed Size | % of original | Time in s |
|---|---|---|---|
| gzip | 294.793.255 | 82.81 | 20.43 |
| bzip2 | 290.093.007 | 81.49 | 141.89 |
| zip | 313.670.439 | 88.12 | 23.78 |
| rar | 305.083.648 | 85.70 | 246.63 |
| lha | 315.669.631 | 88.68 | 64.81 |
| lzma | 283.475.568 | 79.63 | 258.05 |
| lzop | 307.644.076 | 86.42 | 7.89 |
Conclusion
As you can see, the violet lzma-dot is always located at the left side, meaning very good compression. But unfortunately it’s also always at the top, so it’s very slow. But if you want to compress files to send it via mail you won’t bother about longer compression times, the file size might be the crucial factor. At the other hand black, green and grey (gzip, zip and lzop) are often found at the bottom of the plots, so they are faster but don’t decrease the size that effectively.
All in all you have to choose the method on your own. Also think about compatibility, not everybody is able to unpack lzma or lzop.. My upshot is to use lzma if I want to transfer data through networks and for attachments to advanced people, and to use gzip for everything else like backups of configs or mails to windows user.

Martin Scharm
Leave a comment
There are multiple options to leave a comment:
- send me an email
- submit a comment through the feedback page (anonymously via TOR)
- Fork this repo at GitHub, add your comment to the _data/comments directory and send me a pull request
- Fill the following form and Staticman will automagically create a pull request for you:
7 comments
Very detailed Benchmark, especially the choice of the media and plaintext files, nice. For the future I’am sure I will frequently use this site, to choose the optimal compression algorithm.
But I have to add a note: In the rare case I send compressed files to windows users, I use the 7z container. 7z also uses the lzma algorithm and is free software, too.
win: http://7z.org sources: http://p7zip.sourceforge.net/ and available in the Debian,grml an Ubuntu repository.
Thanks for the hint to 7z! I knew I forgot something..
Comparison is unfair and biased towards gzip/bzip2, because you first used tar (practically to join all files into single big file). Other archivers compress each file independently, so they cannot gain an advantage of similarities between files (but they allow you to unpack any file or remove/replace files without repacking the whole archive). If you use tar as the first step for all other archivers as well, results will be much more fair. Rar has a special option
-s(solid archive) which allows you to use inter-file compression. From your tests it seems that similarities between files can affect the result pretty much (especially for/var/logcontent and source code).Your “Binaries” test is invalid. The output of GPG is mathematically pseudo-random and therefore incompressible (as demonstrated). Hence, the result is random noise, identical to your “Rand” test.
Compression of actual binary code files yields substantially different results.
I’m running windows 8 and use quite a small amount of compression, and as of yet I’ve had no problem with lmza, like a comment above stated 7z uses that algorithm and there are numerous programs for windows that will open them and create them with no issue.
I recommend 7z, it uses LZMA algorithm, but adds checksums and archiving capabilities. This adds a little to the overhead, but saves you from having to use tar for archinving, and gives you the reliability of built-in checksums.
As for single files that you don’t need checksums on, I recommend LZMA.
As a note, many of these algorithms you can push further with command line options that most archivers use the default options. This is because, the higher-compression options can take exponentially longer and use more computer resources for only a small gain, and some of them can be very memory and/or processor intensive to decompress.
I’ve done some speed comparison between 7z and zip lately. Zip came out much faster. In some test cases twenty times faster See there: http://99-developer-tools.com/why-zip-is-better-than-7z/