binfalse
Lost my gitosis' post-update
October 8th, 2010Don’t ask me why neither how, but I’ve lost the gitosis’ post-update on my server. So, among others, the .gitosis.conf wasn’t updated anymore…
Ok, let’s start at the beginning. I’m hosting some git repositories on my server using gitosis. Today I tried to create a new repository by editing the gitosis.conf in the gitosis-admin repo, but I couldn’t push the new created repo to the server:
~ % git push origin master:refs/heads/master
ERROR:gitosis.serve.main:Repository read access denied
fatal: The remote end hung up unexpectedlyDamn, looking at the server all rights through the gitosis home seem to be ok. But I was wondering why the $HOME/.gitosis.conf of the gitosis user wasn’t updated!? How could this happen?
After some thoughts I found out, that the link $HOME/repositories/gitosis-admin.git/hooks/post-update was pointing to nirvana:
lrwxrwxrwx 1 gitosis gitosis 97 Aug 23 2009 /home/git/repositories/gitosis-admin.git/hooks/post-update -> /usr/share/python-support/gitosis/gitosis-0.2-py2.5.egg/gitosis/templates/admin/hooks/post-updateSeems that the file /usr/share/python-support/gitosis/gitosis-0.2-py2.5.egg/gitosis/templates/admin/hooks/post-update was deleted through an update (one week ago I updated gitosis 0.2+20090917-9 -> 0.2+20090917-10 ).. Didn’t find an announce of it or any workaround, but I identified a template in /usr/share/pyshared/gitosis/templates/admin/hooks/post-update . So the solution (hack) is to link to that file:
ln -s /usr/share/pyshared/gitosis/templates/admin/hooks/post-update $GITOSISHOME/repositories/gitosis-admin.git/hooks/post-updateJust replace $GITOSISHOME with the home of your gitosis user, mine lives for example in /home/git .
Now every think works fine. If anybody has a better solution please tell me!
Suffix trees
September 20th, 2010Suffix trees are an application to particularly fast implement many important string operations like searching for a pattern or finding the longest common substring.
Introduction and definitions
I already introduced the Z-Algorithm which optimizes the searching for a pattern by preprocessing the pattern. It is very useful if you have to search for one single pattern in a large number of words. But often you’ll try to find many patterns in a single text. So the preprocessing of each pattern is ineffective. Suffix trees come up with a preprocessing of the text, to speed up the search for any pattern.
As expected a suffix tree of the word \(S\in\Sigma^+\) (length \(|S|=m\)) is represented in a data structure of a rooted tree. Every path from root to a leave represents a suffix of \(S\\)$ with \(\$\notin\Sigma\). The union \(\Sigma\cup\$=\tilde{\Sigma}\). Every inner node (except root) has at least two children. Every edge is labeled with a string of \(\tilde{\Sigma}^+\), labels of leaving edges at a single node start with different symbols and each leaf is indexed with \(1\dots m\). The concatenation of all edge labels on a path from root to a leaf with index \(i\) represents the suffix \(S[i\dots m]\).
Definition 1: For each node \(n\):
The path from root to \(n\) is called \(p\)
- The union of the labels at all edges on \(p\) is \(\alpha\in\tilde{\Sigma}^*\)
- \(\alpha\) is label of path \(p\) (\(\alpha=\text{label}(p)\))
- \(\alpha\) is path label to \(n\) (\(\alpha=\text{pathlabel}(n)\))
- instead of \(n\) we can call this node \(\overline \alpha\)
Definition 2: A pattern \(\alpha\in\Sigma^*\) exists in suffix tree of \(S\in\Sigma^+\) (further called \(ST(S)\)) if and only if there is a \(\beta\in\tilde{\Sigma}^*\), so that \(ST(S)\) contains a node \(n\) with \(\alpha\beta=\text{pathlabel}(n)\) (\(n=\overline{\alpha\beta}\)).
Definition 3: A substring \(\alpha\) ends in node \(\overline \alpha\) or in an edge to \(\overline{\alpha\beta}\) with \(\beta\in\tilde{\Sigma}^*\).
Definition 4: A edge to a leaf is called leaf-edge.
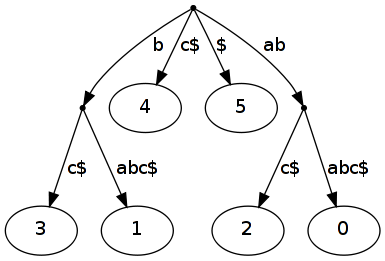
The tree \(ST(ababc)\) contains all suffixes of the word \(ababc\) extended with \(\\)$. This tree is visualized in figure 1.
Building suffix trees: Write only top down
The write-only, top-down (WOTD) algorithm constructs the suffix tree in a top-down fashion.
Algorithm
Let \(\overline \alpha\) be a node in \(ST(S)\), then \(\alpha\) denotes the concatenation of all edge labels on the path to \(\overline \alpha\) (\(\alpha=\text{pathlabel}(\overline \alpha)\)). Each node \(\overline \alpha\) in the suffix tree represents the set of all suffixes that have the prefix \(\alpha\). So the set of pathlabels to leafs below \(\overline \alpha\) can be written as \(R(\overline \alpha)=\{\beta|\beta \in \tilde{\Sigma}^* \wedge \alpha\beta \text{ is suffix of }S\}\) (all suffixes of the set of suffixes that start with \(\alpha\)).
This set is splitted in equivalence classes for each symbol \(c\) with \(G(\overline \alpha, c)=\{c\beta\|c\in \tilde{\Sigma}\wedge c\beta \in R(\overline \alpha)\}\) is the \(c\)-group of \(R(\overline \alpha)\).
Case 1: For groups \(G(\overline \alpha, c)\) that contain only one suffix \(\beta\) we create a leaf \(\overline{\alpha\beta}\) with the index \(|S| - |\alpha\beta|\) and connect it to \(\overline \alpha\) with an edge containing label \(\beta\). Case 2: In groups \(G(\overline \alpha, c)\) with a size of at least two we compute their longest common prefix \(\gamma\) that starts with \(c\) and create a node \(\overline{\alpha\gamma}\). The connecting edge between \(\overline \alpha\) and \(\overline{\alpha\gamma}\) gets the label \(\gamma\) and we continue recursively with this algorithm in node \(\overline{\alpha\gamma}\) with \(R(\overline{\alpha\gamma})=\{\beta|\beta \in \tilde{\Sigma}^* \wedge \alpha\gamma\beta \text{ is suffix of }S\}=\{\beta|\gamma\beta\in R(\overline \alpha)\}\)
Applications
Exact pattern matching
All paths from the root of the suffix tree are labeled with the prefixes of path labels. That is, they’re labeled with prefixes of suffixes of the string \(S\). Or, in other words, they’re labeled with substrings of \(S\). To search for a pattern \(\delta\) in \(S\), just go through \(ST(S)\), following paths labeled by the characters of \(\delta\). At any node \(\overline\alpha\) with \(\alpha\) is prefix of \(\delta\) find the edge with label \(\beta\) that starts with symbol \(\delta[|\alpha|+1]\). If such an edge doesn’t exists, \(\delta\) isn’t a substring of \(S\). Otherwise try to match the pattern with \(\beta\) to node \(\overline{\alpha\beta}\). If \(\alpha\beta\) is not a prefix of \(\delta\) you’ll either get a mismatch denoting that \(\delta\) isn’t a substring of \(S\), or you ran out of caracters of \(\delta\) and found it in the tree. If \(\alpha\beta\) is a prefix of \(\delta\) continue searching at node \(\overline{\alpha\beta}\). If you were able to find \(\delta\) in \(ST(S)\), \(S\) contains \(\delta\) at any position denoted by the indexes of leafs below your point of discovery.
Minimal unique substrings
\(\alpha\) is a minimal unique substring if and only if \(S\) contains \(\alpha\) exactly once and any prefix \(\beta\) of \(\alpha\) can be found at least two times in \(S\).
To find such a minimal unique substring walk through the tree to nodes \(\overline\alpha\) with a leaf-edge \(f\). A minimal unique substring is \(\alpha c\) with \(c\) is the first char of \(label(f)\), because its prefix \(\alpha\) isn’t unique (\(\overline\alpha\) has at least two leaving edges) and every extended version \(\alpha c \beta\) has a prefix that is also unique.
Maximal repeats
A maximal pair is a tuple \((p_1,p_2,l)\), so that \(S[p_1\dots p_1 + l - 1] = S[p_2\dots p_2 + l - 1]\), but \(S[p_1-1] \neq S[p_2-1]\) and \(S[p_1+l] \neq S[p_2+l]\). A maximal repeat is the string represented by such tuple. If \(\alpha\) is a maximal repeat there is a node \(\overline\alpha\) in \(ST(S)\). To find the maximal repeats do a DFS on the tree. Label each leaf with the left character of the suffix that it represents. For each internal node:
- If at least one child is labeled with c, then label it with c
- Else if its children’s labels are diverse, label with c.
- Else then all children have same label, copy it to current node.
Path labels to left-diverse nodes are maximal repeats.
Generalized suffix trees
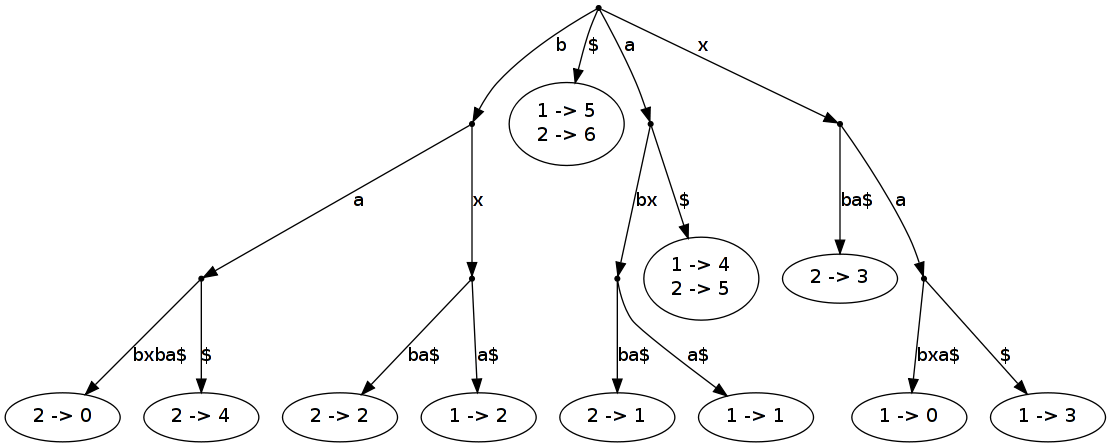
An extension of suffix trees are generalized suffix trees. With it you can represent multiple words in one single tree. Of course you have to modify the tree, so that you know which leaf index corresponds to which word. Just a little bit more to store in the leafs ;) A generalized suffix tree is printed in figure 2 of page one.
Further applications
There are a lot of other applications for a suffix tree structure. For example finding palindromes, search for regular expressions, faster computing of the Levenshtein distance, data compression and so on…
Implementation
I’ve implemented a suffix tree in Java. The tree is constructed via WOTD and finds maximal repeats and minimal unique substrings. I also wanted pictures for this post, thus, I added a functionality that prints GraphViz code that represents the tree.
Cracked the centenary!
September 14th, 2010Wow, the new kernel is the 100th.
~ % grep '^kernel' /boot/grub/menu.lst | wc -l
100(That was the reason why the dist-upgrade took more than an hour!^^)
Bye sidux - welcome aptosid!
September 14th, 2010I just dist-upgraded to aptosid, sidux is gone.
Yesterday the sidux team announced that sidux is dead, but the good news just followed:
As I am sure you are all aware, there have been interesting times for sidux recently. The bad news is that the sidux project is dead. The good news is that aptosid has been aptly born like a phoenix from the ashes and will provide a smooth upgrade for sidux systems. In many ways nothing has changed but our name.
After a long period of silence I already change the OS on my notebook from sidux to grml. It’s a very good alternative, but I decided to wait for an official announcement before deleting my main OS.
Now, the official announce is released, I upgraded my system to aptosid.
First of all I created a aptosid.list in my /etc/apt/sources.list.d/ containing:
deb http://debian.tu-bs.de/project/aptosid/debian/ sid main fix.main contrib fix.contrib non-free fix.non-free vdr
deb-src http://debian.tu-bs.de/project/aptosid/debian/ sid main fix.main contrib fix.contrib non-free fix.non-free vdr
deb ftp://ftp.spline.de/pub/aptosid/debian/ sid main fix.main contrib fix.contrib non-free fix.non-free vdr
deb-src ftp://ftp.spline.de/pub/aptosid/debian/ sid main fix.main contrib fix.contrib non-free fix.non-free vdrAfter wards calling aptitude update to reread the package listings. It notifies me that the new servers couldn’t be verified, I had to install the new keyring:
aptitude install aptosid-archive-keyringIt’s time to upgrade:
aptitude update
aptitude dist-upgradeThat fails at the first time:
Running update-initramfs.
update-initramfs: Generating /boot/initrd.img-2.6.35-4.slh.9-aptosid-amd64
initrd.img(/boot/initrd.img-2.6.35-4.slh.9-aptosid-amd64
) points to /boot/initrd.img-2.6.35-4.slh.9-aptosid-amd64
(/boot/initrd.img-2.6.35-4.slh.9-aptosid-amd64) -- doing nothing at /var/lib/dpkg/info/linux-image-2.6.35-4.slh.9-aptosid-amd64.postinst line 348.
vmlinuz(/boot/vmlinuz-2.6.35-4.slh.9-aptosid-amd64
) points to /boot/vmlinuz-2.6.35-4.slh.9-aptosid-amd64
(/boot/vmlinuz-2.6.35-4.slh.9-aptosid-amd64) -- doing nothing at /var/lib/dpkg/info/linux-image-2.6.35-4.slh.9-aptosid-amd64.postinst line 348.
Running /usr/sbin/update-grub.
Can't exec "/usr/sbin/update-grub": No such file or directory at /var/lib/dpkg/info/linux-image-2.6.35-4.slh.9-aptosid-amd64.postinst line 770.
User postinst hook script [/usr/sbin/update-grub] failed to execute: No such file or directory
dpkg: error processing linux-image-2.6.35-4.slh.9-aptosid-amd64 (--configure):
subprocess installed post-installation script returned error exit status 255As you see, /usr/sbin/update-grub wasn’t found. It is in grub-pc , but I have no idea why there isn’t a dependency so that grub-pc is installed by default!? Not fine but doesn’t matter, just install it:
aptitude install grub-pc
aptitude dist-upgradeIf this is done, just reboot and join the new kernel version 2.6.35 (slh is the greatest!!).
~ % uname -r
2.6.35-4.slh.9-aptosid-amd64Jabber meets Twitter
September 11th, 2010This evening I implemented a XMPP bridge to twitter. So I’ll get all news via IM and can update my status by sending an IM to a bot.
Nothing new, I don’t like the twitter web interface. Neither to read, nor to write messages. So I developed some scripts to tweet from command line. These tools are still working, but not that comfortable as preferred.
Today I had a great thought. At Gajim I’m online at least 24/7, talking with people, getting news etc. So the comparison with twitter is obvious.
After some research how to connect to twitter and jabber I decided to implement the bot in Perl. I still worked a little bit with Net::Twitter, so one side of the connection is almost done. For the other side I used the module Net::Jabber::Bot to implement a bot listening for messages or commands and sending twitter news via IM to my jabber account. The call for the jabber bot looks like:
my $bot = Net::Jabber::Bot->new ({
server => $j_serv
, port => $j_port
, username => $j_user
, password => $j_pass
, alias => $j_user
, message_function => \\&messageCheck
, background_function => \\&updateCheck
, loop_sleep_time => 40
, process_timeout => 5
, forums_and_responses => {}
, ignore_server_messages => 1
, ignore_self_messages => 1
, out_messages_per_second => 20
, max_message_size => 1000
, max_messages_per_hour => 1000});
$bot->SendPersonalMessage($j_auth_user, "hey i'm back again!");
$bot->Start();Most of it should be clear, the function messageCheck is called when a new message arrives the bot’s jabber account. There I parse the text whether it starts with ! (then it’s a command) otherwise the bot schould take the message to update the twitter status.
updateCheck is the background function, it’s called when the bot idles. Here is time to check for news at twitter. It is called loop_sleep_time secs.
The rest is merely a matter of form. News from twitter are jabber’ed, IM’s from the authorized user are twitter’ed. Cool, isn’t it!?
Just download the tool, create a new jabber account for the bot (you’ll get one for example from jabber.ccc.de) and update the jmt.conf file with your credentials.
Of course you need the additional Perl modules, if you also experience various problems with Net::Jabber::Bot try to use the latest code from git://github.com/toddr/perl-net-jabber-bot.git.
The bot could simply be launched by running the Perl script. Send !help to the bot to get some information about known commands.
Just start it at any server/PC that has a network connection.
What comes next? If anyone would provide a server I would like to implement a multiuser tool, maybe with database connectivity!?
