binfalse
IonHunter
November 28th, 2011Some days ago IonHunter came into the world!
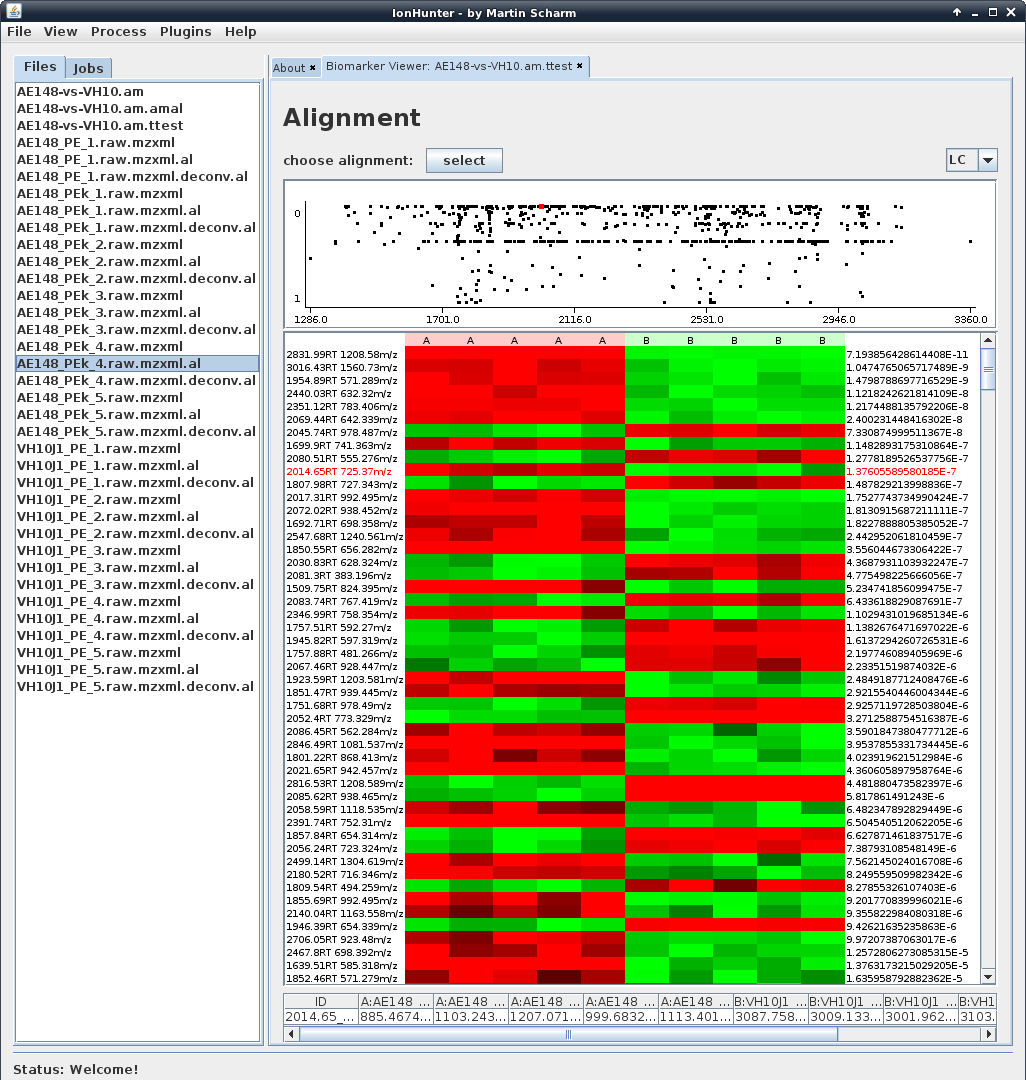
IonHunter is the tool I’m actually developing to receive one of these diplomas. It’s is a software to identify biomarkers in a huge number of LC/MS runs. IonHunter is able to preprocess mass spectrometry data, to merge multiple runs of the same sample and also to correct retention time shifts to align various experiments.
The whole software is modularly designed and easy to extend with further plugins. So developers feel free to join my development!
Currently it isn’t published, but since it’s written in Java it will run on nearly all operating systems. We focused on usability and comfort for mass spec scientists, who will use the tool.
This is just a small announcement for the recently launched website, you might want to take a look at it!? (-;
Small hint for my faithful readers: Subscribe to IonHunters newsletter to stay informed and miss no release!
Presentation using two screens
November 25th, 2011Yesterday I attended a presentation of a colleague, but unfortunately during his speech the PDF viewer on his laptop crashed.
His supervisor told him to use pdf_presenter_console . Don’t know whether you’ve already heard about this tool? It’s able to display the current slide on the beamer-screen while you can see the next slide on your real screen. Generally a nice idea, but the software seemed to be a bit unstable ;-)
Anyway, I always wanted to find a solution to see some notes for a single slide while the slide is active, and today I set to work.
I searched for tools that are able to open two different PDF’s at once, I tried impressive, some vnc hacks, and so on, until I realized that there is already a smart solution on my laptop using the lightweight PDF viewer XPDF!
XPDF has a nice remote feature, if you run it like
xpdf -remote SOMEID presentation.pdf &you can use your terminal to send some commands to the viewer. For example to go to the next slide try the following (see the COMMANDS section of XPDFs man page):
xpdf -remote SOMEID -exec nextPageGreat, isn’t it!? (if you receive the error error: "nextPage" file not found scroll down to XPDF is buggy)
I think the rest is clear, open two different XPDF-instances, one for the notes and one for the presentation itself:
usr@srv % xpdf -remote NOTES notes.pdf &
usr@srv % xpdf -remote PRESENTATION presentation.pdf &and define some keys to scroll through the PDFs. You could use xbindkeys to bind the keys to the commands, for example I use F9 to go to the next slide and added the following to my ~/.xbindkeysrc :
"xpdf -remote PRESENTATION -exec nextPage && xpdf -remote NOTES -exec nextPage"
m:0x10 + c:75After running
xbindkeys -f ~/.xbindkeysrcI’m able to go to the next slide by pressing F9 . To find the keycodes for some keys you may use xbindkeys -k or xev . Take a look at the documentation for more information (GER).
Of course presentation.pdf and notes.pdf should have the same number of pages ;-)
XPDF is buggy
The -exec flag didn’t work for me, returning the following error:
usr@srv % xpdf -remote SOMEID -exec nextPage
error: "nextPage" file not foundI tried version 3.02 and also 3.03. The problem is located in the XPDF wrapper script, located in /usr/bin/xpdf . If you take a look at the contents you’ll find the following lines (in my case it’s 25ff):
while [ "$#" -gt "0" ]; do
case "$1" in
-z|-g|-geometry|-remote|-rgb|-papercolor|-eucjp|-t1lib|-ps|-paperw|-paperh|-upw)
cmd="$cmd $1 "$2"" && shift ;;
-title)
title="$2" && shift ;;
-m)They simply forgot to define the -exec parameter to take an argument. So nextPage is not seen as argument for -exec and XPDF tries to find a file called nextPage that is obviously not present. To patch this you just need to add -exec like:
while [ "$#" -gt "0" ]; do
case "$1" in
-z|-g|-geometry|-remote|-rgb|-papercolor|-eucjp|-t1lib|-ps|-paperw|-paperh|-upw|-exec)
cmd="$cmd $1 "$2"" && shift ;;
-title)
title="$2" && shift ;;
-m)or just use xpdf.real directly and skip the wrapper:
usr@srv % xpdf.real -remote SOMEID -exec nextPageSince modifying files in /usr/bin isn’t a good idea I recommend to just substitute xpdf for xpdf.real in your ~/.xbindkeysrc .
That’s it for the moment, I wish you a nice presentation ;-)
Compress Google's Reader
November 14th, 2011If you are using Google’s Reader to aggregate news feeds you might have recognized that Google re-engineered its feed-reader to fit into the styles of other Google-services.
The new interface slimmed a bit and is more lightweight, but I’m arguing about the large white-spaces! Too much space is unused and to less information is presented. Such disadvantages are also discussed at other places.
First I thought I’ll get used to it, but now I decided to change it on my own. So I created a small user script for the Firefox extension Greasemonkey. Here you see the difference (click the images for larger versions):
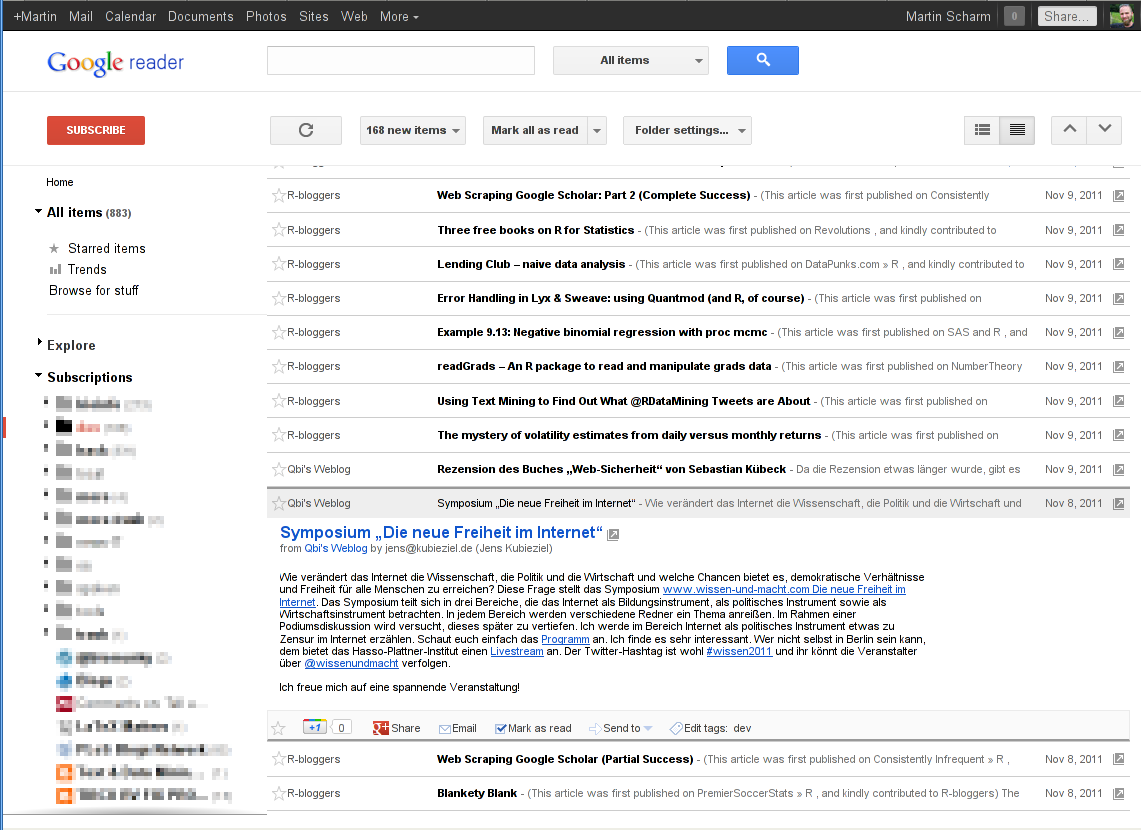
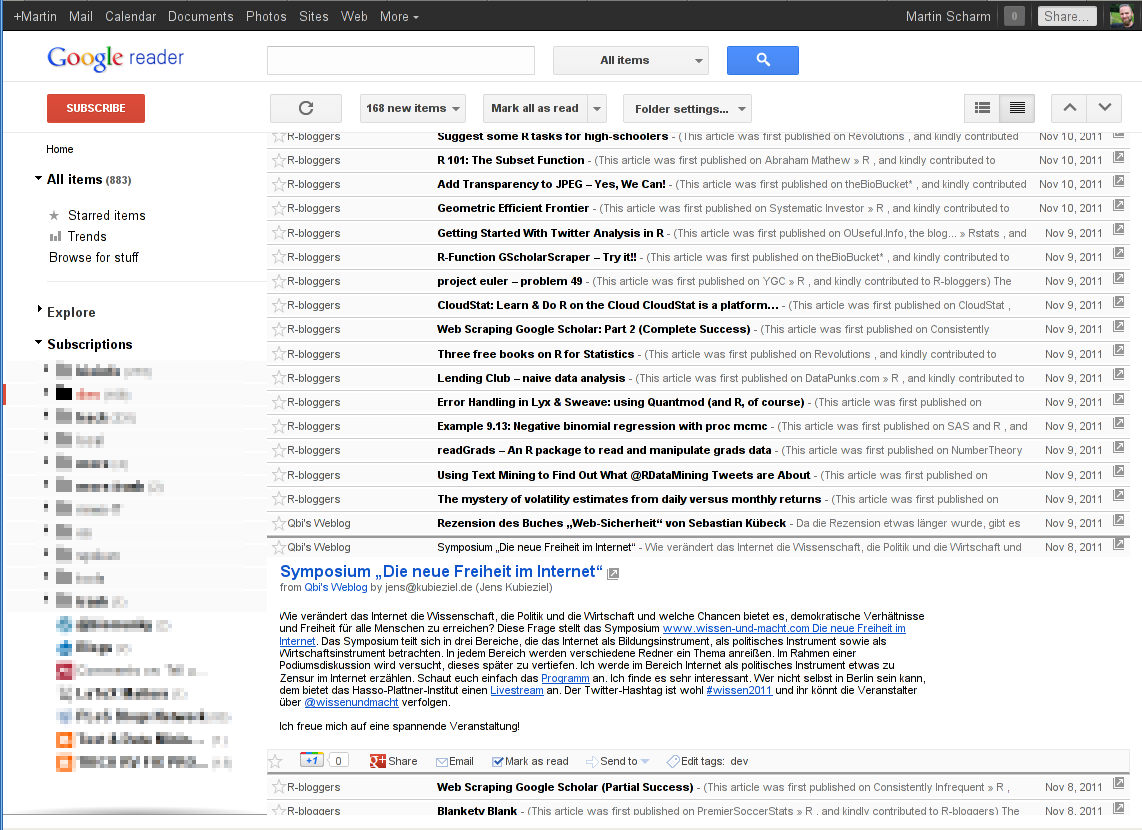
So you see, there is less space at the top of the page and single entries got closer together. The script is available in the download section, all you need is the browser Firefox and its extension Greasemonkey. If you have both installed just click the following link to the download and Greasemonky will ask you to install my short script. That’s it for the moment ;-)
Update 22.11.2011: Updated the UserScript to support googles new layout.
Sharing a Wifi connection
November 13th, 2011Due to different circumstances I had to figure out how to share a wireless connection with some wired clients. And what should I say, that’s a very simple task ;-)
The scenario
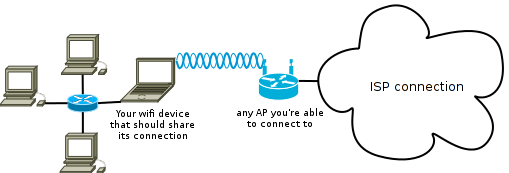
With your notbook you are able to connect to an AP with access to the internet, but other machines within your network infrastructure don’t have access to the outside world, and you want your local machines to also use this wireless connection of your notebook. Figure 1 visualizes this use case.
The setup
First of all I have to admit I don’t know which software needs to be installed. Since I previously did some network hacks with this notebook I didn’t have to install something that wasn’t actually present, but I think you’ll need something like network-manager-gnome , dnsmasq-base and dnsmasq-utils .
And of course you also need a Linux notebook (e.g. with a Debian or an Ubuntu) with wifi hardware, an AP with internet connection and a RJ45 Ethernet port on the notebook for the wired connection to other PC’s.
The first thing you should do is to connect to the AP, so your notebook will be able to access the WWW.
The next step is to connect another machine to your notebook using a network cable. This machine needs to be configured as a DHCP-client. (Since this might be any operating system of your choice I don’t describe the configuration, but most systems should already be configured correctly)
Now you have to setup a shared connection on your notebook. Right-click the network indicator icon in your systems panel (next to your clock) and choose Edit Connections…, compare to figure 2.
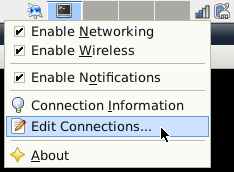
This will open a new window with connections you still configured. In the Wired tab click Add to install a new shared connection, see figure 3.
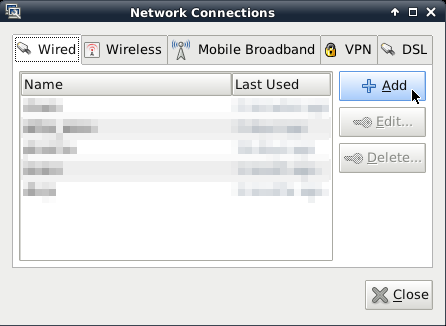
You’ll see another window to configure this new connection. Just give it a name like share and choose the method Shared to other computers in the IPv4 Settings tab, as shown in figure 4.
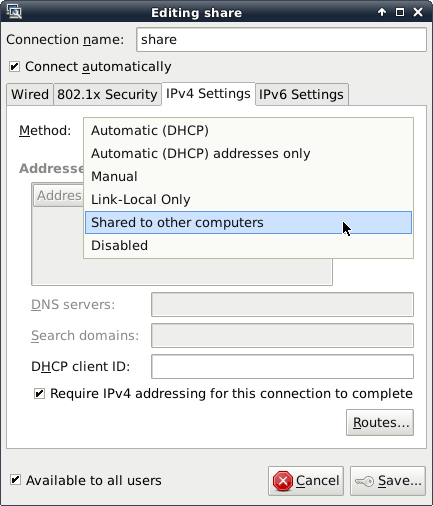
Last but not least open a terminal and add a new entry to the nat-table:
sudo iptables -t nat -A POSTROUTING -j MASQUERADEThat’s it, using this newly created connection you’re able to connect your clients behind your notebook through your wireless connection.
They are following you!
August 10th, 2011Recently there was a discussion with the privacy officer of Hamburg. He was arguing about people using Google-Analytics, but he also tracks his visitors on his public website. So are you anonymous? Of course not! Lets have a look at the why.
What's the problem?
Many webmasters analyze their website with Google-Analytics. This is a service of Google, very easy to use. All you need to do is insert a small script somewhere into your HTML-code:
<script type="text/javascript">
var _gaq = _gaq || [];
_gaq.push(['_setAccount', 'SOME_ID']);
_gaq.push(['_trackPageview']);
(function() {
var ga = document.createElement('script'); ga.type = 'text/javascript'; ga.async = true;
ga.src = ('https:' == document.location.protocol ? 'https://ssl' : 'http://www') + '.google-analytics.com/ga.js';
var s = document.getElementsByTagName('script')[0]; s.parentNode.insertBefore(ga, s);
})();
</script>This code tells the visitors browser to download a script from http://www.google-analytics.com/. That is while you visit this website, you additionally visit Google’s website in the background. Google of course recognizes this visit and knows which website you accessed. That is of course very cool for webmasters, they’ll get very detailed statistics about their visitors without any own work. Which article is favored most, should articles be published in the morning or in the evening, where do the visitors come from, how much time do they spend on the site and so on. Visitors don’t even know that Google follows them on nearly every website they visit. So Google is able to create very extensive profiles of every web user. Where do I come from? Am I interested in technical or political topics? Which videos do I like at YouTube? How frequently do I visit YouPorn? Based on my clicks it’s easy to guess my gender (shoes or cars?), my age (SpongeBob or cure), my professional (stock market news or music)… Do you have an account at Twitter? Google-Analytics also tracks user generated content. Together with some personal sites at Xing or LinkedIn or a blog at bloggers.com it’s easy to get a comprehensive profile of a single web user.
So Google is the bastard?
Oh not in the slightest! There are a lot of these companies. The previous mentioned privacy officer for examples tracks it’s users with IVW. The IVW uses a similar technique, you add a small image, a so called web bug, to your site:
<img id="ivw_pixel" src="http://heise.ivwbox.de/cgi-bin/ivw/SOMEID">Since it is exactly 1 pixel it is not visible to the user, but your browser nevertheless loads it from ivwbox.de and so they get notified if you visit this specific website. Prominent customers are also Heise, Playboy, Xing, Ebay, Bild.de and a lot more (click the links to get some statistics). So IVW also creates extensive profiles of you! Do you really want to connect you professional Xing profile with Bild.de or Playboy? ;-)
But not enough, you know these funny pictures:
How often did you see one of these buttons today? Do you know a website that doesn’t have a like button (except mine)? Lets have a look to the HTML code:
<iframe src="https://plusone.google.com/u/0/_/+1/SOMESTUFF" allowtransparency="true" hspace="0" id="SOMEID" marginheight="0" marginwidth="0" name="SOMENAME" style="STYLE" tabindex="-1" vspace="0" scrolling="no" width="100%" frameborder="0"></iframe>
[...]
<iframe src="http://platform.twitter.com/widgets/tweet_button.html#_=ID" title="TITLE" style="STYLE" class="CLASS" allowtransparency="true" scrolling="no" frameborder="0"></iframe><script type="text/javascript" src="http://platform.twitter.com/widgets.js"></script>
[...]
<iframe src="http://www.facebook.com/plugins/like.php?href=ID" style="STYLE" allowtransparency="true" scrolling="no" frameborder="0"></iframe>
[...]
<script src="http://www.stumbleupon.com/hostedbadge.php?s=1"></script><iframe src="http://www.stumbleupon.com/badge/embed/1/?url=ID" style="STYLE" allowtransparency="true" scrolling="no" frameborder="0"></iframe>Wow, while we visit one single website, our browser notifies Google, Twitter, Facebook and StumbleUpon about our short visit. Crazy, isn’t it? And there are much more networks that offer such buttons. Or have a look at this picture:
Each button is loaded from foreign webservers. I hardly can see any benefit for the user or the webmaster!?
How to defend?
There is no protection, power off all your electronics and go back to the stone age! (Or get amish) Ok, that’s hard and somewhat impossible these days. But there are some possibilities to minimize the tracking.
For example some Firefox extensions like NoScript prevent your browser loading scripts from foreign servers (see Google-Analytics).
But you’ll also load these buttons and iframes, because this is simple HTML. Here you need another extension like AdBlockPlus. This allows you to define rules for blocking specific content, e.g. everything that comes from facebook. But keep in mind that these companies own different domains, like facebook.com, facebook.net or fbcdn.net. And even if you think you got all of them, there are a lot more. There is also a filter list for social media stuff available at Chrome Adblock (yes, comes from Google, but does its job…).
If you are not running Firefox or you don’t want to install a bunch of plugins, you can also send these request to nirvana. For example unix-guys might add lines like this to their /etc/hosts :
192.168.23.23 facebook.comEvery time your browser wants to load a script from facebook.com he sends a request to 192.168.23.23 , which hopefully doesn’t exists. Do the same for all the other profiler.
Fear?
Don’t be frightened now, but be aware! You should carefully decide what to publish about yourself and others around you. And of course take care of your privacy. Some days ago we went to Berlin for a meeting, when a colleague received a message via facebook on his BlackBerry from a friend asking what he’s doing in Berlin!? Looks like his smart-phone told facebook its GPS position without his approval!? That’s scary, isn’t it!
So think twice while exploring the world wide web ;-)
